
BrandZap
George Little
Case Study
A civil engineering firm, Carson Engineering, had accumulated years of valuable internal knowledge, but most of it was difficult to access in the moments when people needed it most.
Like many companies in the AEC space, the firm’s operational knowledge lived across a mix of local file servers, Word documents, PDFs, resumes, proposals, templates, reference materials, and team memory. The information was technically available, but not practically usable. If a project manager needed to reference an old proposal, find a letter template, confirm who had relevant project experience, or understand how similar work had been priced in the past, the process often started with searching through folders, asking around on Teams, or copying from an old file that looked “close enough.”
That kind of workflow can function for a while, especially in smaller teams where institutional knowledge is still concentrated among a few senior people. But as the firm grew, the gaps became more visible. Different people were solving the same problems in different ways. Proposal language varied. Pricing decisions were difficult to compare. Templates were inconsistently used. Newer team members had limited access to the context that senior staff carried in their heads.
The goal of the project was not to replace the firm’s entire technology stack or force a large-scale digital transformation. The firm already had tools, habits, and constraints that needed to be respected. Instead, the opportunity was to create a practical AI-enabled knowledge layer on top of the existing system — one that could make the firm’s current knowledge easier to search, reference, and reuse.
The firm did not have a simple documentation problem. It had a usability problem.
There were plenty of documents already in place: proposals, resumes, project references, internal templates, community hearing letters, design references, guidelines, and other frequently used materials. But those files were not structured in a way that made them easy to search or compare. They had been created over time for specific use cases, not as part of a unified knowledge system.
This became especially clear with proposals. In theory, past proposals should have been one of the firm’s most valuable knowledge sources. They contained scope language, project context, pricing, line items, timelines, client details, and clues about how the firm had positioned similar work in the past. But in practice, most proposals also contained large amounts of repeated boilerplate language. If entire proposal documents were uploaded directly into an AI system, the model would have to sift through repetitive copy before finding the few details that actually mattered.
That created two problems. First, the AI experience became noisy and inefficient. Second, the repeated boilerplate risked distorting the results, because the model could over-weight language that appeared frequently while missing more useful project-specific information. Your transcript described this clearly: simply feeding the system whole documents burned unnecessary token usage and made the answers less focused.
The technical environment added another layer of complexity. The firm was not operating like a cloud-native SaaS company. Much of the content lived in local file servers and Microsoft Word documents, with no clean API layer or modern knowledge management infrastructure. The firm also did not want to purchase a separate AI subscription for every employee. The solution needed to work within those realities rather than require a major platform shift.
The project began by treating the existing file system as a source of knowledge rather than something that needed to be replaced.
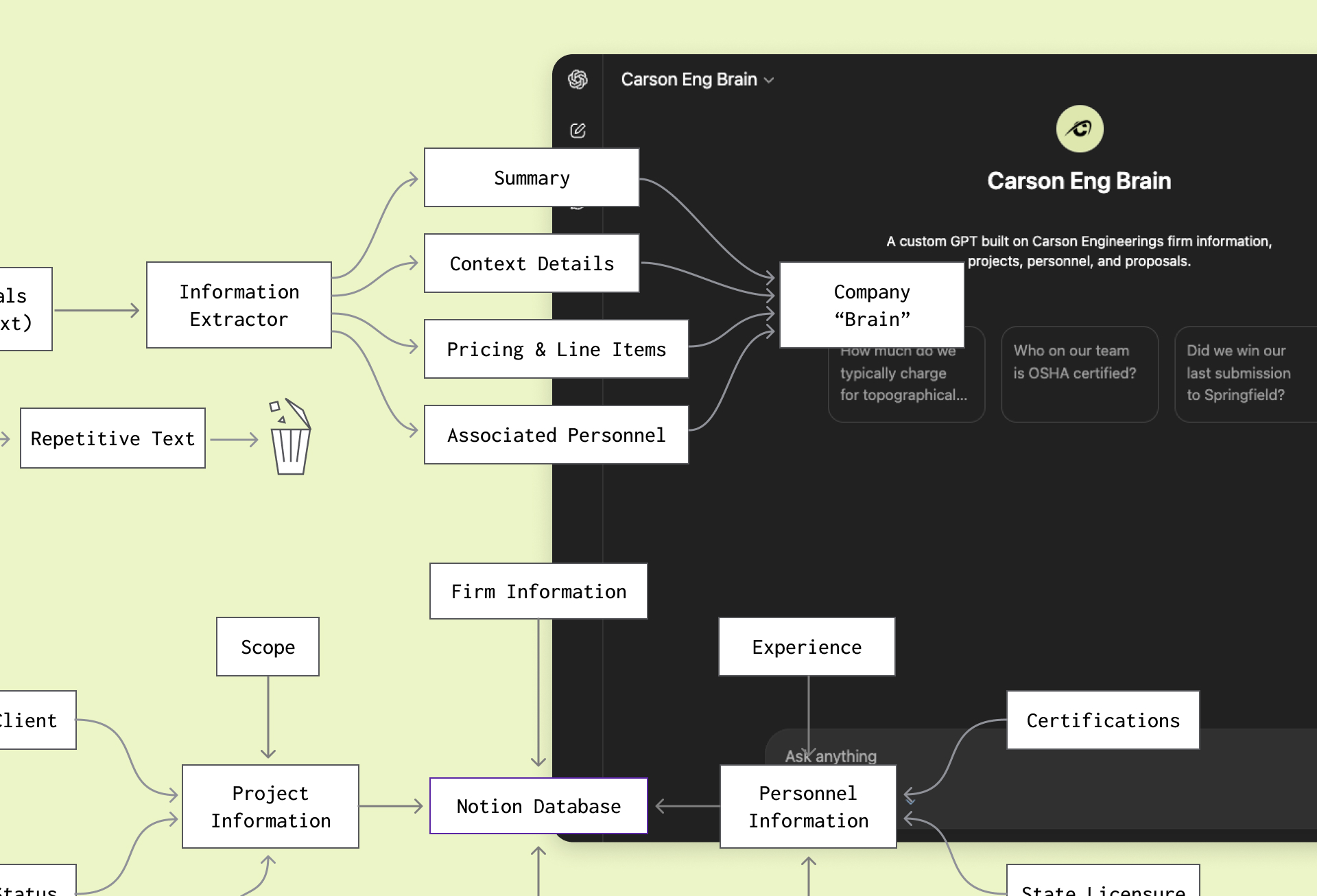
The first step was to identify the types of information that would actually be useful in day-to-day work. This included templates, memos, proposals, employee resumes, project references, credentials, past experience, and internal guidelines. These materials were then grouped and organized into clearer categories, making it easier to understand what the AI system would eventually need to reference.
From there, the strategy was to build a lightweight knowledge layer between the firm’s raw documents and the chatbot interface. Rather than asking an AI model to interpret messy files every time someone asked a question, the system would process those files in advance, extract the useful information, and convert it into cleaner, structured knowledge.
This was the core shift: the system was not designed to be a chatbot pointed at a pile of documents. It was designed as a structured knowledge base with a conversational interface.
One part of the system focused on people, credentials, and project experience.
For a civil engineering firm, questions about internal expertise are common and important. A proposal might require knowing who has worked on a certain type of project, who has a specific certification, or which team members have relevant municipal experience. Before this project, that information existed across resumes, PDFs, project records, and individual memory. The AI system needed a cleaner way to connect those dots.
To support that, team member information was structured into PDFs, markdown files, and database-style records. In parallel, a set of Notion databases was created to organize relationships between people, projects, credentials, and project types. This created a simple but useful relational model: projects could be connected to project managers, project types could be connected to relevant experience, and credentials could be associated with individual team members.
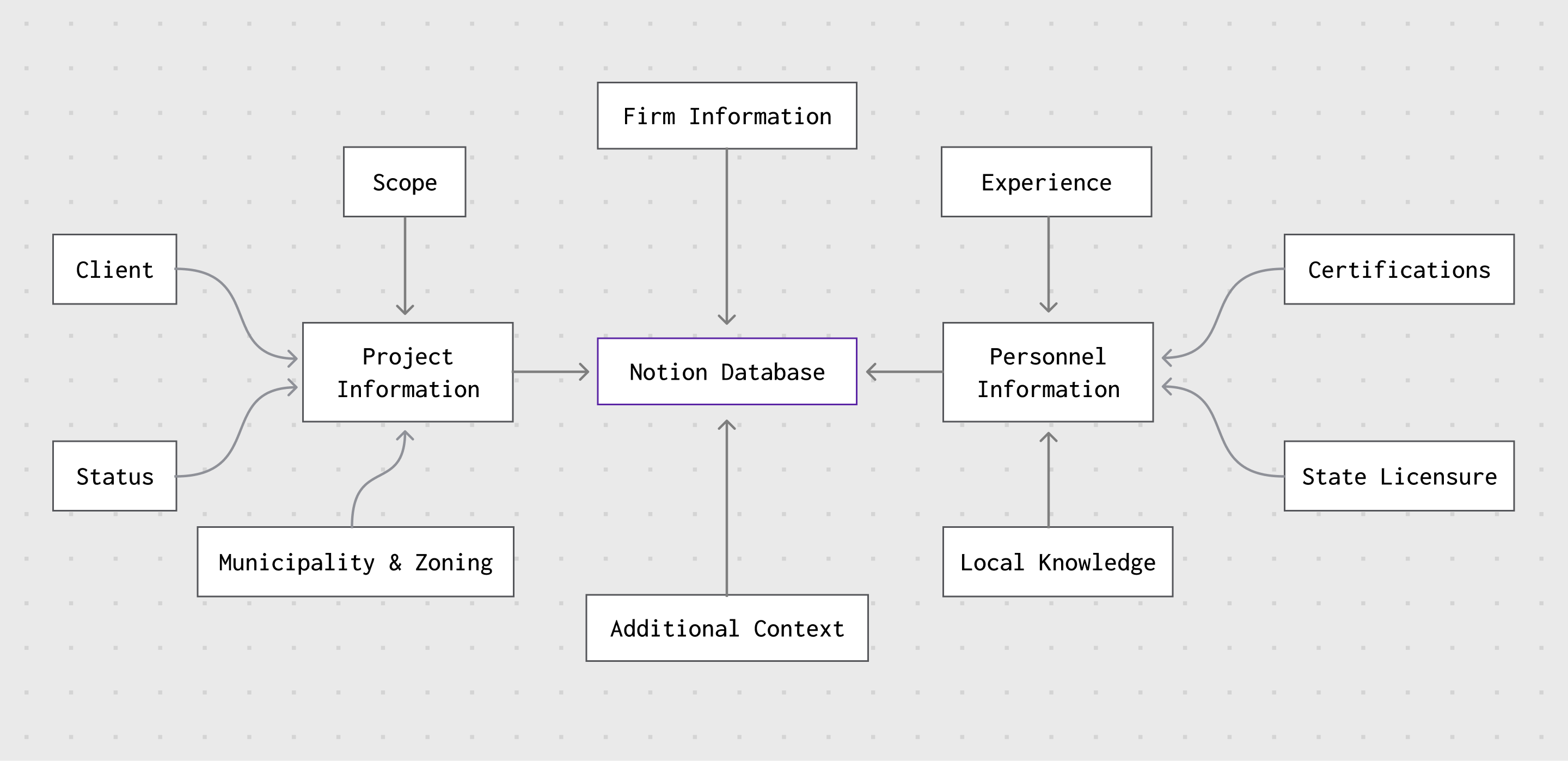
That structure gave the chatbot something more reliable to reference. Instead of searching through long resumes or brochures every time someone asked a question, it could look up cleaner tables and summaries. The result was a more useful internal assistant — one that could help answer questions like:
Who has worked on projects like this before?
Do we have experience with this type of municipality?
Which team members have a specific certification?
What similar projects can we reference in a proposal?
This made the system more than a document search tool. It became a way to make the firm’s internal experience easier to surface.
The proposal archive became one of the most important parts of the project.
At first, the obvious idea was to give the AI system access to the firm’s previous proposals. But once the documents were reviewed, it became clear that raw proposal files were not the best knowledge format. They were too long, too repetitive, and too inconsistent. The useful details were there, but they were buried.
.png)
To solve that, BrandZap created an intermediate interpretation process. Each proposal could be passed through a workflow that read the document, removed unnecessary structural noise, and summarized the key information into a cleaner format. Instead of storing the proposal as a full document, the system extracted the details that mattered most:
Project type
Scope of work
Pricing and line items
Client or municipality details
Relevant language or project-specific context
Comparable project references
These summaries were then compiled into a running markdown-based knowledge file. Over time, this created a much more useful representation of the firm’s proposal history. The chatbot no longer had to dig through full documents filled with repeated boilerplate. It could reference a cleaner, more structured layer of proposal intelligence.
This also made the system more practical for real-world use. When someone asked whether the firm had done a similar project before, the AI could point them toward relevant examples. When someone asked how a comparable project had been scoped or priced, the system could provide a directional answer and identify source material for deeper review.
The goal was not to have AI replace professional judgment. It was to give project managers and firm leadership a better starting point.
One of the most important parts of the project was designing around the firm’s existing technical limitations.
Because the source files were mostly Word documents stored on a local file server, there was no clean cloud-based pipeline for ingestion. To work around that, a lightweight automation process was created using Make.com. The process allowed batches of Word documents to be uploaded, stripped down to their core content, moved temporarily into a more API-accessible format, summarized, and then removed once processing was complete.
The final output was a versioned knowledge base file that could be uploaded into the custom GPT and republished for internal use. This created a simple update loop: new files could be processed periodically, the knowledge base could be refreshed, and the chatbot could continue improving without requiring a fully automated enterprise data pipeline.
This was a deliberately pragmatic solution. It still required some manual maintenance, but the tradeoff was worthwhile. Even if the update process took about an hour once a month, that was far more efficient than having employees repeatedly search through folders, message colleagues, or recreate proposal language from scratch.
Once the knowledge base was structured, the chatbot itself could remain simple.
The firm did not need a flashy interface or a custom software product. It needed an accessible place where employees could ask practical questions in plain language and receive answers grounded in the firm’s own work. A custom GPT provided a lightweight shared entry point that could be updated over time and used by employees without requiring a more complex software rollout.
This gave users a more natural way to interact with internal knowledge. Instead of needing to know where a file lived, what it was named, or who last worked on something similar, they could ask a direct question:
“Have we done a parking lot study like this before?”
“What should we reference for this proposal?”
“Who has experience with this type of project?”
“How have we priced similar work in the past?”
The chatbot could then respond with a useful summary, point toward comparable projects, and help the user understand where to look next.
The experience was intentionally modest. It was not positioned as a perfect source of truth or a fully autonomous proposal engine. It was a faster, more useful first step — a way to turn scattered institutional knowledge into something employees could actually use.
One of the more interesting outcomes came from the proposal data.
The original goal was to make past proposals easier to find and reference. But once proposals were summarized into a structured format, pricing patterns became easier to see. Similar projects could be compared more easily. Scope language could be reviewed side by side. Line items and fees could be understood in context.
That created a new kind of question for the firm: What do we usually charge for this kind of work?
Before the knowledge base, answering that question often depended on memory, guesswork, or finding the right old file. After the proposal summaries were created, the AI system could provide a directional pricing reference based on actual past work.
This did not make the system perfect. As noted in the transcript, the chatbot could sometimes blend internal proposal data with more general assumptions about market pricing. But even that became useful when handled properly. Users could ask follow-up questions, compare what the firm had charged against what the broader market might suggest, and use the response as a prompt for better internal discussion.
At one point, the system was asked to evaluate the firm’s pricing patterns across the available proposal data. Its assessment suggested that the firm had often been underpricing work relative to the apparent scope. That insight was not magic — it came from making existing information easier to compare. But surfacing it through a conversational interface made the pattern easier to recognize and act on.
The final result was a practical AI knowledge base that worked within the firm’s existing constraints.
It did not require a complete migration to a new cloud platform. It did not require every employee to adopt a new project management system. It did not depend on perfect data pipelines or enterprise AI infrastructure. Instead, it created a structured, maintainable layer between the firm’s existing files and the people who needed to use them.
The system helped reduce friction across several common workflows:
Finding relevant project examples
Identifying team members with specific experience
Referencing credentials and resumes
Reviewing proposal language
Comparing past scopes and pricing
Creating a more consistent starting point for new work
The biggest value was not that the chatbot could answer every question perfectly. The value was that it gave people a better place to begin.
Instead of starting with a blank document, a messy folder search, or a message to a senior colleague, employees could start with organized context from the firm’s own history. That changed the experience of using internal knowledge from something slow and fragmented into something more immediate and practical.
This project shows that useful AI implementation does not always require a massive digital transformation.
For many firms, especially in industries like architecture, engineering, and construction, the most valuable knowledge already exists. The problem is that it lives in formats and systems that make it hard to reuse. By extracting, structuring, and refreshing that knowledge, even a relatively lightweight AI system can make a meaningful operational difference.
The lesson is simple: before building something new, make what already exists easier to understand.
For this firm, that meant turning years of scattered documents into a practical internal resource — one that helped employees find answers faster, reuse institutional knowledge more consistently, and make better-informed decisions around proposals, staffing, and pricing.





-2000.webp)
-1200.webp)